

























What Is a Canonical URL and How Is It Used in a SEO Strategy?

A canonical URL is a key factor for dealing with duplicate content on a web page, something that, like cannibalization, affects the positioning of the page in search engine results pages (SERPs).
Its importance is such that the main search portals such as Google, Microsoft and Yahoo joined forces to create them in order to easily and quickly solve content problems.
What is a canonical URL
A canonical tag (rel="canonical") is an HTML fragment of the source code that defines the main version for duplicate, near-duplicate and similar pages. That is, if you have content available at different URLs that is the same or similar to each other, you can use these tags to point out which is the main version that should be indexed.
How a rel=canonical tag looks
The syntax of the canonical tags, which are located in the 'head' section of the web page, is as follows:
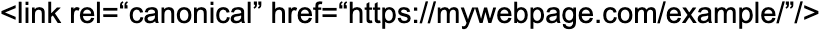
Thus, each part of that code means the following:
- link rel=“canonical”: the link on this tag is the master (canonical) version of this page
- href=“https://mywebpage.com/example/”: the canonical version can be found at this URL.
Why canonical tags are important for SEO
It is well known that search engines do not like duplicate content at all, because it forces them to decide:
- What version of a page to index.
- Which version of a page to position for relevant queries.
- Whether they should consolidate the link juice (or link equity) on one page or divide it among several versions.
Therefore, having a lot of duplicate content will affect the crawl budget, so the search engine will waste time tracking different versions of your same page instead of discovering other more important content on the page.
Also, if you don't specify a canonical URL, the search engine itself will identify what it thinks is the best version or URL of a piece of content. This is not recommended because it might select a version that you don't want to be canonical.
Best practices for canonicalization
There are five important points that you should take into account when canonizing a URL.
1. Using absolute URLs
John Mueller from Google says that it is advisable not to use relative paths with the linking element rel="canonical". Then, you should use the following structure:
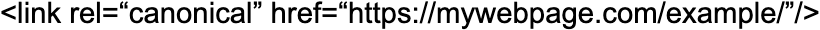
Instead of:
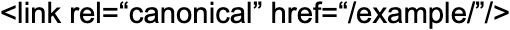
2. Using lowercase URLs
Since search engines treat uppercase and lowercase URLs as different URLs, you should be sure to force lowercase URLs on the server and then use them in canonical tags.
3. Using the right version of the domain (HTTPS vs HTTP)
In case you have switched to SSL, you have to make sure not to declare any non-SSL URLs (i.e. HTTP) in the canonical tags because it could confuse and cause unexpected situations. Thus, if you are on a secure domain you should make sure that you use the next version of the URL:
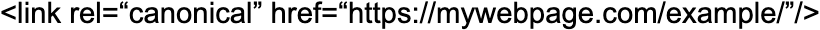
Instead of:
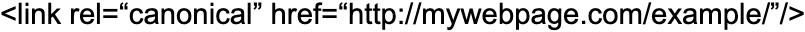
4. Using self-referencing canonical tags
Although self-referencing canonical tags are not mandatory, their use is recommended, as John Mueller again points out. They function as a canonical tag on a page that points to itself. For example, if the URL were:

So a self-referencing canonical URL would be:
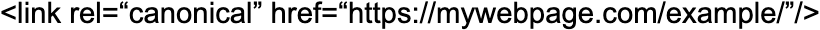
Nowadays, almost all CMS's (like Acai Shop, WordPress, PrestaShop, Joomla or Wix, among others) add self-referencing URLs automatically.
5. Use only one canonical tag per page
If a page has different canonical tags, search engines will ignore them.
How to implement canonical tags
There are five ways of specifying canonical URLs, which are known as canonicalization signals.
1. HTML rel=“canonical” tag
This is the most obvious and simple way to specify a URL that is canonical. Just add it to the section of the chosen page:

2. HTTP header
In certain documents, such as PDF files, there is no way to set canonical tags in the page header because, basically, they have no section. In these cases, you have to use the HTTP header to place the canonical.
3. Sitemap
Non-canonical pages should not be listed on the site maps, since search engines consider the pages included in the sitemap as suggested canonicals.
4. 301 redirect
As we saw earlier in the article on SEO cannibalization, using 301 redirects is a great way to divert traffic from a URL with duplicate or similar content to a URL that is canonical.
5. Internal links
The way you link between pages on your site is a sign of canonicalization. Again, John Mueller explains it quite well in the following video:
The more consistent these signals are, the easier it will be for search engines to decide on the ideal canonical URL.
How to avoid common canonicalization errors
As this topic is a bit complex, avoid the following errors when canonicalising URLs.
1. Block the canonicalized URL by robots.txt
Blocking a URL in robots.txt will only prevent Google from crawling it and you won't see any canonical tags in that URL. This prevents the transfer of link juice from the non-canonical URL to the canonical one.
2. Configure the canonicalized URL as ‘noindex’
Never mix ‘noindex’ with rel="canonical", as these are contradictory orders. If you do not want to index but canonicalize a URL, the ideal is to use a 301 redirection.
3. Set an HTTP 4XX status code for the canonicalized URL
This practice has the same result as the previous section. The search engine will not see the canonical label and will transfer link juice to the canonical version.
4. Canonicalization of all paginated pages to the main page
The paginated pages should not be canonicalised to the first page of the series, but self-referencing canonicals should be used on all paginated pages. Also, using rel=prev/next tags is a plus.
5. Not using canonical labels with hreflang
Hreflang tags are used to specify the language and target area of a web page. Thus, you should use a canonical page in the same language or the best possible substitute language if there is no canonical page for the same language.
6. Having many rel=canonical tags
If you have multiple rel=canonical tags in a URL the search engine will ignore them, since they are incorporated into a system at different points. This can also happen with canonicals added with JavaScript.
If you don't have a certain canonical URL in the HTML response and then add a rel=canonical tag with JavaScript this should be respected when the browser renders the page.
However, if you have a canonical specified in HTML and you exchange the preferred version with JavaScript, the result is that you will be sending confusing signals to the search engine.
7. Rel=canonical outside of
The rel=canonical tag should only appear in the of a document, otherwise it will be ignored and may even cause more complex errors to the URL.

How to find and solve problems of canonicalization
Since making canonicalization errors is very common, the ideal thing to do would be to audit the website regularly to address such problems. Several of these errors that flag the auditing tools are as follows.
1. Canonical points to 4XX
This is a warning that is activated if one or more pages are canonicalised to a 4XX URL, since search engines do not index 4XX pages because they do not work. Therefore, they ignore any canonical tag pointing to those pages and end up indexing the wrong (non-canonical) version of it.
To fix this you have to check the affected pages and replace the dead canonicals links (4XX) with links to working pages (200) that you want to index.
2. Canonical points to 5XX
This is a warning that is activated if one or more pages are canonicalised to a 5XX URL, since the HTTP 5XX status codes warn of server problems, resulting in an inaccessible canonical page. The search engine is unlikely to index inaccessible pages, so it may ignore the canonical code.
To fix this, just replace any erroneous canonical URLs with valid ones. Then check the server for misconfigurations if the canonical specified seems correct. This can be a temporary problem if the crawl occurred when the site was down for maintenance or the server was overloaded.
3. Canonical points to redirect
This is a warning that is activated if one or more pages are canonicalised to a redirected URL, because canonicals have to point to the most authoritative version of a page. This does not happen with URL redirection. Thus, search engines may misinterpret or ignore it.
To fix this, replace the canonicals with direct links to the highest authority version of the page (in other words, one that returns an HTTP 200 status code and does not redirect).
4. Duplicated pages without canonical
This is a warning that is activated if there are one or more duplicate or very similar pages that do not specify a canonical version because the search engine will try to identify the most suitable version to show in the search results. And it is possible that this is not the version you want to index.
To fix this you need to check the groups of duplicates, choose a canonical version that should be indexed in the search results and specify this as the canonical version in all duplicates (and add a self-referential canonical tag to the canonical version).
5. Hreflang to non-canonical
This is a warning that is activated if one or more pages specify a non-canonical URL in their hreflang entries, as links in hreflang tags must always point to canonical pages. This is because linking to a noncanonical version of a page from hreflang entries could confuse and mislead search engines.
To solve this, simply replace the links in the hreflang annotations of the pages affected by your canonical.
6. Canonical URL has no internal inbound links
This is a warning that is activated if one or more specified canonical URLs do not have internal inbound links, since orphaned canonical URLs are inaccessible to website visitors. Somewhere on the site they have to be directed to a non-canonical version of the page.
To fix this, simply replace any internal links to canonical pages with direct links to the canonical one.
7. Non-canonical page in sitemap
This is a warning that is activated if one or more non-canonical pages appear in the Sitemap, since search engines think that non-canonical URLs should not be included in the Sitemap. The reason for this is that they see the sitemap pages as canonical suggestions, so only the pages you want to index should be included in the Sitemaps.
To fix this, just remove the non-canonical URLs from the sitemap.
8. Non-canonical page specified as canonical
It is a warning that is activated if one or more pages specify a URL that is canonical that is also canonical to a different page. This causes a "chain of canonicals" where page A is canonicalised to page B, which is simultaneously canonicalised to page C.
These canonical chains confuse and mislead search engines, which could result in them misinterpreting or ignoring their specifications.
To fix this, the non-canonical links in the canonical tags of the affected pages must be replaced by direct links to the canonical. For example, in the previous case you would only have to replace the canonical link on page A with a link to page C.
9. Open Graph URL does not match canonical
This is a warning that is triggered if there is a mismatch between the specified canonical and the Open Graph URL on one or more pages, because if the Open Graph URL does not match the canonical URL, a non-canonical version of a page will not be shared with RR.
To fix this, the Open Graph URL must be replaced on the pages affected by the canonical. Also, make sure that the two URLs are the same, that they are absolute and that they use the protocols http:// or https://.
10. Canonical from HTTPS to HTTP
This is a warning that is activated if one or more secure pages (HTTPS) specify an unsecured version (HTTP) such as the canonical and, since the former is a positioning factor, it makes perfect sense to specify secure versions of pages as canonicals whenever possible.
To fix this, you have to redirect the HTTP page to the HTTPS equivalent. If this is not possible, you should add a rel=canonical link from the HTTP version of the page to the HTTPS.
11. Canonical from HTTP to HTTPS
This is a warning that is activated if one or more non-secure (HTTP) pages specify a secure (HTTPS) version such as the canonical, as HTTPS is always preferable to HTTP. Having an HTTP version of a page and then specifying the HTTPS version as canonical is illogical.
To solve this problem, it would be necessary to implement a 301 redirection from HTTP to HTTPS. You would also have to replace any internal links to the HTTP version of the page with links directly to the HTTPS version.
12. Non-canonical pages receive organic traffic
It is a warning that is activated if one or more non-canonical pages are in the search results and get organic search traffic (which should not happen).
This is because either the canonical URL tags are misconfigured or the search engine has decided to ignore the specified canonical.
To fix this you have to check that the rel=canonical tags are set correctly in all the reported pages. If not, use the URL inspection tool of Google Search Console to check if they consider that the specified canonical URL is really canonical.
Final thoughts
As you may have noticed, canonical tags are not so complicated to understand after reading an article like this, are they? Just keep in mind that these tags are not a directive but a signal to search engines. After all, search engines might choose a different canonical one than the one you set. Now you know everything about what a canonical URL is.

